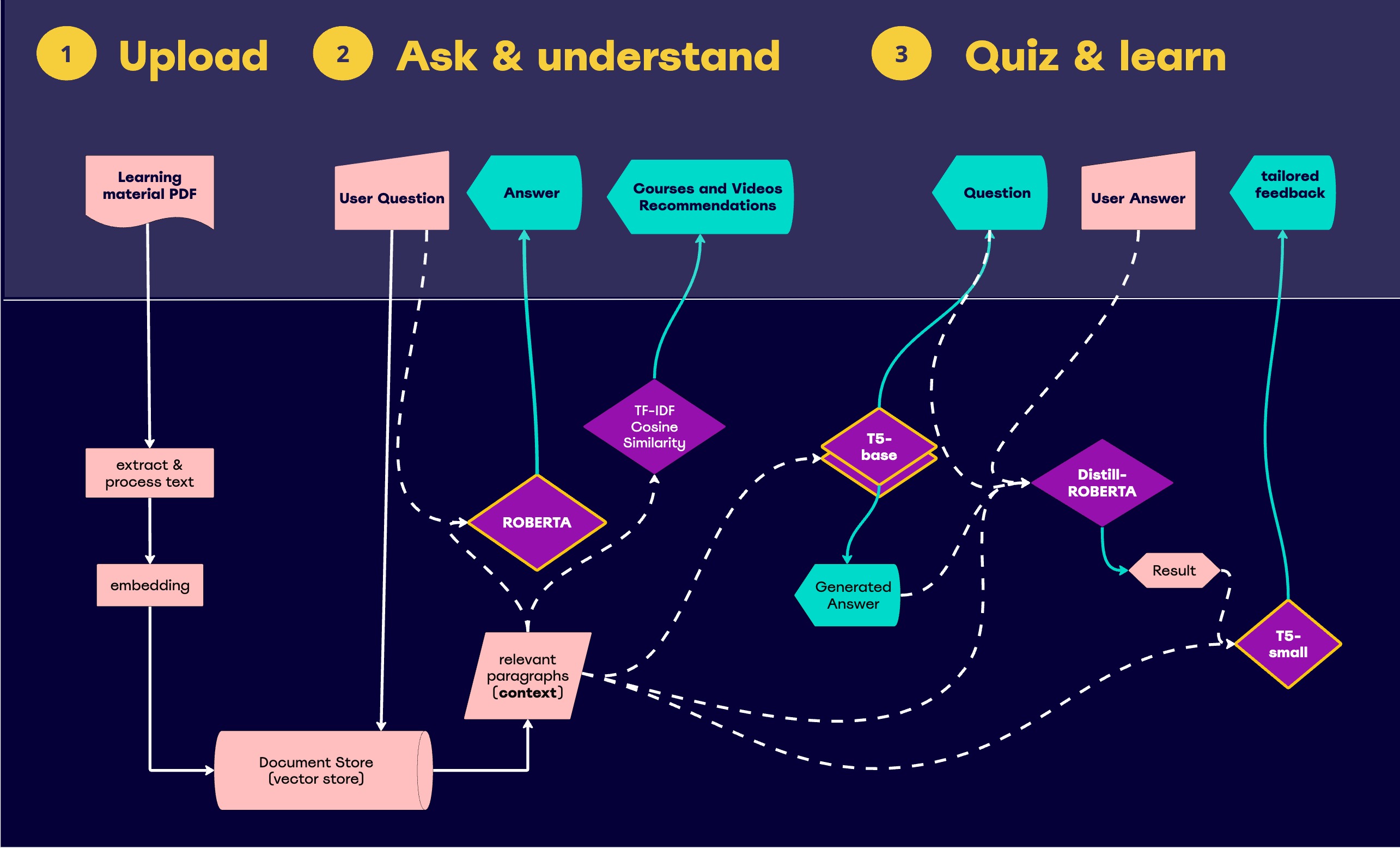
In this project, we created a smart agent that answers questions from users based on uploaded PDF documents. These PDFs act as a knowledge base, and the system pulls information directly from them to answer queries. To achieve this, we used the RoBERTa language model, which is fine-tuned on the SQuAD dataset. This dataset contains question-answer pairs where the answers are segments of text from Wikipedia articles.
Extractive vs. Generative Models
RoBERTa is an extractive model, meaning it pulls information directly from the given text, rather than generating new content. This makes it a strong choice when accuracy and text faithfulness are important. However, in more complex scenarios, where answers need to be paraphrased or where a broader understanding is required, generative models may be more effective. In general, the more sensitive the task, the higher the need for faithful, word-for-word responses.
Quiz Generation with T5 Model
We then moved on to developing a quiz generator. For this, we selected the T5 model, which is well-suited for sequence-to-sequence tasks like question generation. We fine-tuned the model using two datasets: SQuAD and NewsQA. After testing both the "small" and "base" versions of T5, the base model showed better performance, so we focused on that for further development.
Overcoming Quiz Generation Challenges
One of the challenges we faced was that, while the model could generate grammatically correct questions, these questions often didn't match the context. To address this, we adopted a two-model system. The first T5 model identified plausible answers from the text, and the second model generated questions based on these answers. This method significantly improved the relevance and quality of the generated questions.
Answer Evaluation & User Feedback
For quiz feedback, we experimented with open-source models like EleutherAI/gpt-neo, which initially seemed promising. However, due to slow performance and resource limitations, we developed a two-step solution for evaluating answers.
Step 1: Answer Evaluation
Evaluating user answers is a complex task, with few available datasets for training. Our evaluation system works in three steps:
- Direct Match – It checks for exact matches with the correct answer.
- Cosine Similarity – This eliminates irrelevant answers using the 'sentence-transformers/all-MiniLM-L6-v2' model, which works best for short texts.
- Nuanced Evaluation – The 'Giyaseddin/distilroberta-base-finetuned-short-answer-assessment' model assesses tricky cases, like incomplete or contradictory answers.
Step 2: Feedback Generation
To help users learn from their quizzes, we trained a T5-small model on the BillSum dataset for summarization. This model summarizes the evaluation results and the context from the PDF, so users can easily understand their mistakes. The output summary is dynamically adjusted based on the length of the context, ensuring clear and cohesive feedback.
Conclusion
The development of this system required a mix of advanced machine learning models, careful fine-tuning, and innovative problem-solving. We’re continuously refining the models to ensure accurate answers, relevant questions, and helpful feedback.
Mentor: Rashmi Carol Dsouza
Team: Oula Suliman, Sonia, Arpad Dusa