Learning to dance is hard work, even harder if you (like me) have two left legs. I have always wondered how professional dancers usually practice new choreographies. For beginners it must be even harder, right?
Experienced instructors at dance classes often divide dance routines into segments for learners, making it easier to focus on small parts at a time and rehearse. Manually segmenting dance movements can be a tedious task and relies on the extensive expertise and training of the instructors. However, their job could be easier and more focused on the creative side of the choreography, if the segmentation could be automatized. For people who learn dance moves from online videos from platforms like YouTube or TikTok, figuring out where each movement starts and ends can be frustrating.
This idea inspired us while choosing a final project. For our project at the Data Science Retreat Berlin boot camp, we set out to tackle automatic dance movement segmentation. We want to ease the job of instructors and anyone learning to dance and revolutionize how dancers, especially those learning independently, practice and master routines. As with many ideas, there was already a solution out there. We found a research paper Automatic Dance Video Segmentation for Understanding Choreography by Koki Endo et al, and they solved this problem already. We have decided to implement a solution based on their work. At the end of the day, this is how science works (acknowledging and building on previous knowledge).
In the above-mentioned article, the authors present a new tool to help dancers learn from videos. It’s designed to automatically break down dance videos into segments. This makes it much easier for dancers, especially beginners, to practice choreography. It automatically identifies segmentation points within dance videos, removing the need for manual editing. This approach could transform how people learn dance, making video-based practice more accessible and enjoyable for everyone.
In simple terms, we trained a model to do this automatically. Once the model is ready, we can use it to analyze our dance videos. The output will give us timestamps showing where each movement ends. With these timestamps, we can display them in a custom video viewer, loop through sections, rehearse, and analyze the movements. Sounds simple, right?
The proposed tool uses deep learning to automate this process. It works by analyzing both visual and audio information from the video, identifying points where movements naturally divide. The result? A model that enables dancers to efficiently practice step-by-step.
How the method works?
The method takes a dance video as input and breaks it into segments. It gives back a probability score if the current frame coresponds to the end of a move segment. It does this by analyzing two main features of the video:
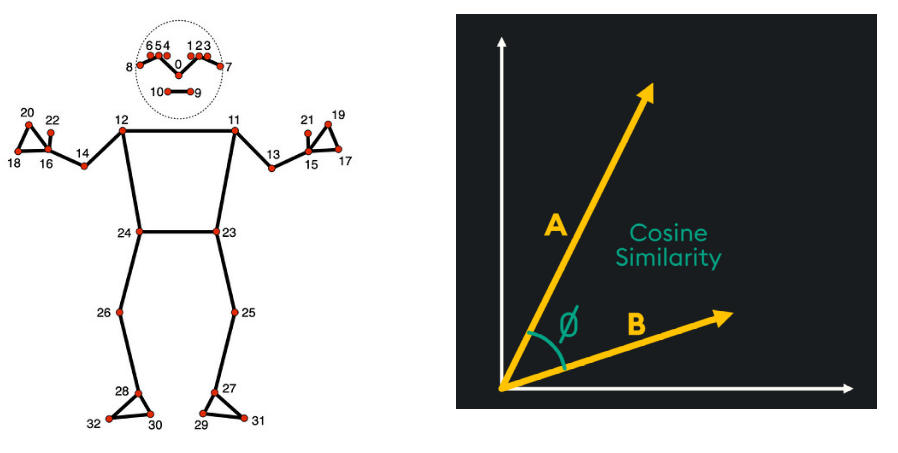
- Visual features: the system tracks the dancer’s body movements frame by frame. Using a Python library called mediapipe, it identifies key body points and creates “bone vectors,” which represent how different parts of the body are positioned. This data helps the tool recognize movement patterns, allowing it to detect transitions between movements.
- Audio features: since dance often follows the rhythm of the music, the audio plays a big role. The system creates a "Mel spectrogram" of the music (using a Python library called librosa), which breaks down the song’s rhythm and beats. This helps the model identify points in the music that align with the start of new movements.
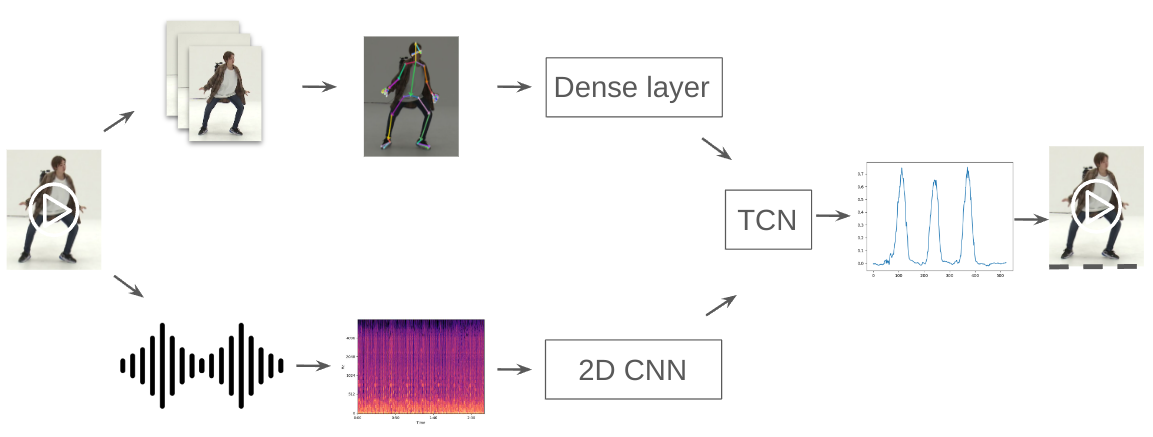
Finally, both visual and audio data are processed by a neural network model called a Temporal Convolutional Network (TCN). The TCN detects patterns over time, allowing it to spot where one movement ends, and the next one begins. It outputs a “segmentation probability score” for each frame. The highest values in this score signal represent a new movement in the choreography. In simple terms, the model combines visual and audio information to find where each movement in the dance routine begins and ends.
Building a dataset to train the model
For the model to work, the authors (Koki Endo et al) needed a well-labeled dataset of dance videos. They chose the AIST Dance Video Database, which includes many dance genres. The videos were manually annotated by 21 experienced dancers who marked segmentation points. These manual annotations were then averaged into a "ground truth" to help the model learn accurate segmentation.

This wide variety of annotations ensured that the system could account for different interpretations of choreography. It also made the model more reliable across different genres and styles.
Testing the model's performance
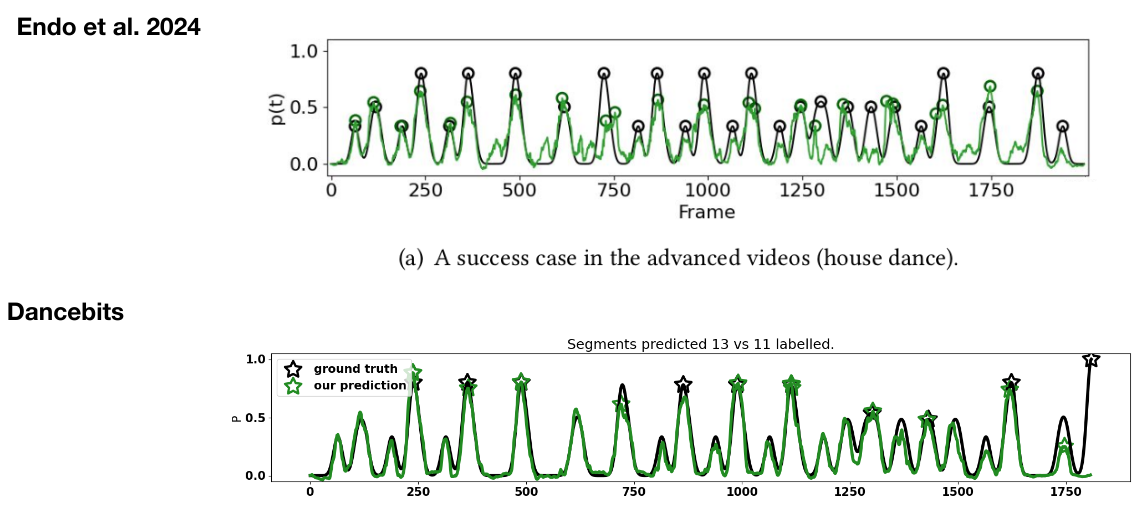
To check how well the tool works, Koki Endo et al tested it on part of the annotated dataset. Results showed that the tool achieved about 80% accuracy in predicting segmentation points. They also found that using both visual and audio features together was far more effective than relying on just one.
However, the results varied by dance genre. Dances with strong beats and clear rhythms, like hip-hop or house, were easier for the tool to segment accurately. Smoother, more fluid styles like ballet or jazz were more challenging, as their movements were less connected to strict beats.
We were able to train a model, which performed better than the original model. Our interpretation is that since we didn’t experiment that much with hyperparameters, it comes from using a different library (mediapipe instead of Alphapose) for the bone vector calculations.
A new application for dance practice
We created a web interface for using the model. Key features include playing and looping through segments, mirroring the video (which is especially helpful for practicing), and giving a similarity score to provide feedback on the dancer’s performance. You can see the full live demo by clicking the link at the end of this text.
Cosine similarity
We implemented a feature to check how closely a rehearsing dancer’s movements match the teaching video. It calculates the cosine similarity of the bone vectors between the two videos. This means it measures how aligned the body positions are frame by frame. High cosine similarity indicates the dancer is closely following the instructor’s movement. This feature helps provide instant feedback on movement accuracy.
Since the similarity score is just a number, like a percentage, aiming for a perfect 100% match isn’t necessary. Dance movements naturally vary, so an ideal match would be a range rather than an exact number. To improve the model, as a next step would have been to build a dataset where dance teachers label similarity scores (based on the student's performance) as "good," "average," or "needs improvement." This would be a machine-learning project of its own.
To improve this feature even further, the cosine similarity score could be used to analyze specific body parts separately. For instance, the system could individually assess leg, arm, and torso alignment. Then, it could suggest focused improvements, like "pay more attention to your left arm" or "improve leg alignment." This targeted feedback could guide dancers more effectively, helping them refine specific movements.
Potential limitations and future improvements
While the tool is groundbreaking, it has some limitations. Segmentation accuracy varies depending on the dance genre, with smoother styles (meaning the movements are more continuous, like ballet for example) being harder to segment. The tool also needs clear, high-quality video and audio. Poor-quality recordings could lead to less accurate segmentation.
Future improvements could involve refining how the tool interprets the relationship between movement and music. Adding more genres and training on a broader range of styles would also enhance its versatility.
Expanding beyond dance could make the model much more useful. It could support sports recovery and physiotherapy, guiding people through movements at home. This would help with remote rehab and fitness routines. The model could also work in training, like tracking form in yoga or martial arts (potentially any sport). With adjustments to handle different movements, it could reach a wider audience. Emphasizing this versatility would make it appealing outside of dance.
Conclusion
This automatic dance segmentation tool is a valuable advancement for dancers. It simplifies video-based dance practice by breaking routines into manageable segments, making dance more accessible to learners.
By combining visual and audio features, the tool identifies transition points in choreography, allowing dancers to learn one movement at a time. With continued refinement, this tool could revolutionize how dancers, especially those learning independently, practice and master routines while always remembering what a fun and creative activity it is.
Mentor: Antonio Rueda-Toicen
Team members: Cristina Melnic,
Paras Mehta,
Arpad Dusa
Our work was based on: Koki Endo, Shuhei Tsuchida, Tsukasa Fukusato, Takeo Igarashi: Automatic Dance Video Segmentation for Understanding Choreography
Special thanks go to Koki Endo for providing the video labels